I recently attended an interesting conference hosted by the Atlanta Fed on
Employment and the Business Cycle, where I had the pleasure of discussing this paper by Rob Shimer:
Wage Rigidities and Jobless Recoveries. This was a fun paper to read, and I learned something new and interesting.
The backdrop for the paper is, of course, the recent financial crisis and associated recession. The level of GDP has essentially recovered its pre-recession level, while employment appears not to have recovered at all--these joint dynamics are referred to as a "jobless recovery."
The hypothesis Shimer puts forth is this: [1] there was a shock (or shocks) that led to an evaporation in the value of the economy's capital stock; and [2] real wage growth is "sticky" in the sense that it appears insensitive to macro shocks.
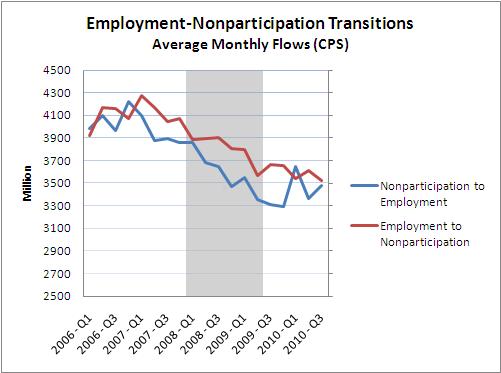
The type of evidence that lends some support for this latter hypothesis is displayed in the following diagram (also used by Bob Hall in his talk).
As an aside, I personally do not find such evidence wholly compelling. First, I think that composition bias is a big problem in the aggregate data; i.e., the first people to be let go in a recession are the least productive. Second, I have personal experience in the construction sector that leads me to believe that actual wage flexibility is much greater than what is recorded in official statistics. But in any case, I'm not here to argue about the evidence; let me take it as a fact that real wage growth is "sticky" in the sense described above. (Note: the basic story goes through as long as the real wage is not perfectly flexible).
To begin, consider a standard neoclassical growth model and let us consider a point on along the balanced growth path, where output and wages are growing, and employment (per capita) remains fixed over time.
Now, imagine that we shock the economy by evaporating some fraction of its capital stock. The subsequent transition dynamics are familiar to macroeconomic theorists and there is no need to describe them in detail here. The important thing is that real wages initially fall (since labor productivity falls and wages are flexible) and that the economy eventually returns to its balanced growth path.
Next, let us repeat the experiment, but assuming instead that real wages continue to grow along their balanced growth path (that is, the real wage does not respond to the shock). What do the subsequent transition dynamics look like? My own expectation was that the economy would once again return to its balanced growth path, but that the period of transition would be extended owing to the assumed rigidity in the real wage. Everyone I quizzed about this had the same expectation.
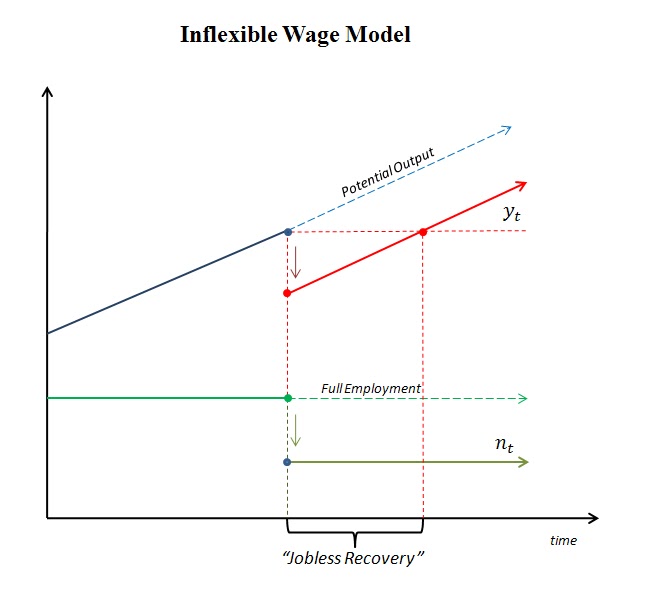
Surprisingly, to me at least, this intuition turns out to be completely wrong! Output and employment drops on impact, but then output stays along its new balanced growth path, with employment remaining below full employment forever; see the following diagram.
Now, I have to admit that my first thought at reading this result was that it must surely be wrong. But, of course (this is Shimer after all), it turns out to be correct. You can verify this for yourself by reading the paper. But as this will probably take more effort than you're willing to expend, let me give you a much simpler example that conveys the basic intuition.
An OLG Model
People live for 2 periods and they value consumption only in the last period of life; write the utility function of a person born at date t as
Ut = ct+1. This simplifying assumption implies that the young save all their income.
The young are each endowed with one unit of time, which they supply inelastically to the labor market. Let
N denote the population of young workers; and assume that
N remains constant over time. Let
wt denote the real wage at date t.
The old are in possession of the economy's capital stock
Kt. The old hire young labor at the prevailing wage, produce output, and then consume the profit (the return on capital). Capital depreciates fully after it is used in production.
There is a standard neoclassical production technology
Y = F(K,N) satisfying
Y = f(k)N, where
k = K/N is the capital labor ratio. Let
F be Cobb-Douglas and let
0 < α < 1 denote capital's share of output. Then we have
f '(k)k = αf(k).
Now, the demand for labor satisfies:
wt = FN(Kt,Ntd) and the supply of labor satisfies
Nts = N. In a competitive equilibrium, the real wage must satisfy:
[1] wt = FN(Kt,N) = (1 - α)f(kt); where
kt = Kt/N.
In what follows, I set the exogenous growth rate to zero, since doing so is not important for explaining the main result. Now, as the young save all their earnings, it follows that the next period capital stock (per young person) is given by:
[2] kt+1 = (1 - α)f(kt)
In other words, the dynamics are equivalent to the standard Solow model we teach to undergrads. The nondegenerate steady state capital-labor ratio is characterized by:
[3] k* = (1-α)f(k*) [Note that
k* = w* ]
Alright then. Begin at a point on the balanced growth path (here, a steady state with zero growth) and evaporate some capital, so that
K0 < K*. This is a crude way to model the impact effect of a financial crisis. The transition dynamics should be familiar to any student of the Solow model; in particular, see [2]. In a decentralized version of this model, employment remains fixed at
N, but the real wage (and the real wage bill) initially declines, before transitioning back to their original steady state values.
O.K., now let's repeat this experiment, but this time under the assumption that the real wage remains fixed at its initial steady-state value,
wt = w* for all t. In this case, the level of employment
N0 < N is determined the demand for labor; i.e.,
[4] w* = FN(K0,N0) = (1 - α)f(k*) = k*
Condition [4] implies that the capital-labor ratio remains unchanged; i.e., K
0/N
0 = k
*. That is, the demand for labor declines in proportion to the decline in the value of capital. Since the real wage is fixed, this also implies that the aggregate wage bill declines in the same proportion. And since the wage bill here constitutes the saving that finances new capital, we have:
[5] K1 = w*N0 = K0 [since
N0 = K0/k* and
k* = w* ]
In other words, the capital stock remains forever fixed at
K0 < K* and the level of employment remains forever fixed at
N0 < N.
This is a permanent depression! If we extend the model to allow for exogenous growth, the level of employment remains depressed, but the level of output grows and eventually recovers its original level (this is the jobless recovery phase). However, the level of output remains forever below its "potential." Interesting.
Labor Market Search
One of the drawbacks of the model above is that both firms and workers stand to gain by negotiating the real wage downward following the shock. There is nothing in this model that prevents agents from exploiting these gains from trade, so ruling it out exogenously seems wrong (even if it is deemed realistic).
To address this shortcoming, Shimer extends the neoclassical model with the competitive labor market replaced by a search market, with bilateral meetings and negotiations. One of the nice things about the search specification is that the real wage may remain fixed in an equilibrium (if the shock is not too large). In other words, there need not be any inefficiency associated with a fixed wage at the individual level (though, it may induce an inefficiency at the aggregate level).
Shimer shows that the search model with rigid real wages generates dynamics that closely resemble those generated by a standard neoclassical model with rigid real wages. There appears to be an added force at work in the search model though. In particular, the combination of the negative shock and fixed real wage (along its balanced growth path) serves, in a way, to redistribute bargaining power from firms to workers. This is bad news for job creation, because the returns to investing in recruiting activities is now diminished, leading to a prolonged decline in employment. Sounds familiar.
In my view, this is an argument that deserves to be taken seriously. How seriously depends on how seriously one takes the "rigid real wage" hypothesis. Christopher Pissarides has criticized the assumption on the grounds that, in reality, real wages for new hires (or job changers) appear to be quite flexible relative to workers who remain employed. And, as Pissarides points out, the wages of incumbent workers do not factor into hiring decisions in a search model (assuming that the firm is not credit constrained). The key price as far as recruiting is concerned is the expected wage demands of future employees; and these appear to be relatively flexible.
This is all very interesting stuff. Almost makes me want to work in the area again!
P.S. The policy implications also turn out to be very interesting. Despite the "Keynesian" sticky wage property of these models, fiscal stimulus in the form of an increase in government purchases has the effect of crowding out capital investment, with no effect on employment. On the other hand, fiscal policies that subsidize business sector hiring (like a cut in the payroll tax) appear to be effective.




































{kind=link}